场景文字识别模型梳理
mileistone
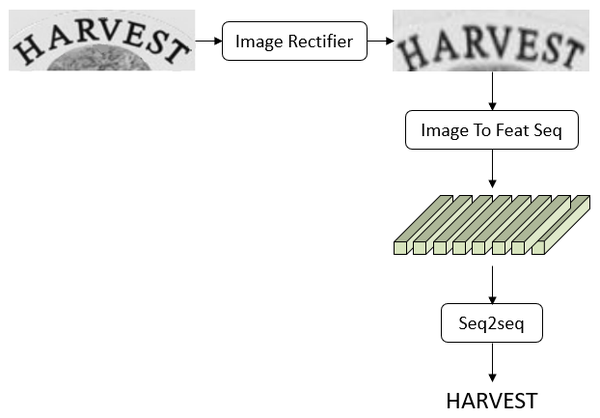
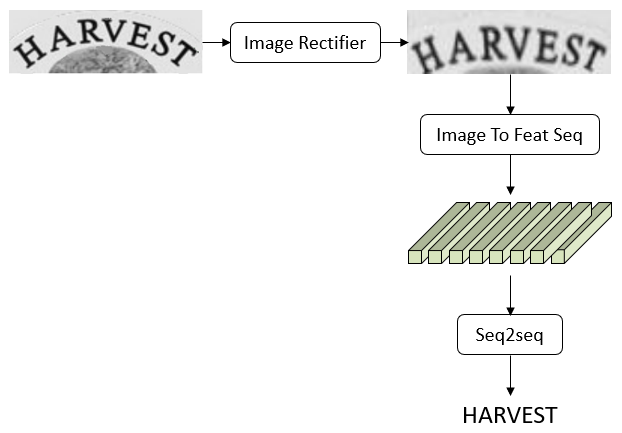
场景文字识别(scene text recognition),简称为STR。最近对STR做了一下调研,相关论文可以记录在scene text recognition papers中。当前流行的各种方法经过抽象和模块化,可以得到文章开头的pipeline图和文章末尾的framework。
具体而言,STR可以分为三个模块Image Rectifier、Image To Feature Sequence、Seq2seq。
Image Rectifier
这个模块隐式地学习如何把文字图像进行矫正,使得模型对于弯曲和视角具备一定的鲁棒性。该模块输入和输出均为图像。该模块是可选项,可要可不要。
Image To Feature Sequence
这个模块将图像映射为一个特征序列,即输入为图像,输出为特征序列。该模块可以使用CNNs、RNNs、self-attention等模块。比如只使用CNNs;或者前半部分CNNs,后半部分RNNs;或者前半部分CNNs,后半部分self-attention;或者各种排列组合。
CNNs部分,可以只使用类似VGG、ResNet这样的backbone,也可以在后面加一个类似于FPN这样的neck对不同satage的特征进行融合。
RNNs部分,一般使用LSTM或者GRU,可以只单向建模,也可以双向建模。
self-attention部分,可以使用简单的non-local或者使用Transformer的encoder。
Seq2seq
这个模块将特征序列转换为文字序列,即输入为特征序列,输出为文字序列。
一般方法有CTC、RNN decoder、transformer decoder,基本上机器翻译使用的方法这里都可以借用。
### 1. Image Rectifier
#### 1.1. STN + TPS
### 2. Image to Feature Sequence
#### 2.1. CNNs
##### 2.1.1. Backbone
###### 2.1.1.1. VGG
###### 2.1.1.2. ResNet
##### 2.1.2. Neck
###### 2.1.2.1. FPN
#### 2.2. RNNs (bidirectional or unidirectional)
##### 2.2.1. LSTM
##### 2.2.2. GRU
#### 2.3. self attention
##### 2.3.1. [non local](https://arxiv.org/abs/1711.07971)
##### 2.3.1. Transformer encoder
### 3. Seq2seq
#### 3.1. [CTC](https://www.cs.toronto.edu/~graves/icml_2006.pdf)
#### 3.2. RNNs
#### 3.2.1. vanilla
#### 3.2.2. equipped with attention module
#### 3.3. Transformer decoder
#### 3.4. [ACE](https://arxiv.org/abs/1904.08364)原文见我的个人博客场景文字识别模型方法梳理,排版会更好一些。
写于2020-12-18。
本内容版权归作者mileistone所有
相关见解
哇咔咔

评论